
Software Stack
Cấu trúc phần mềm của SINGA bao gồm hai cấp độ chính, cấp thấp backend classes và cấp giao diện Python. Hình 1 mô tả chúng cùng với phần cứng. Cấu tạo backend cung cấp cấu trúc dữ liệu cơ bản cho các mô hình deep learning, khái quát phần cứng để kế hoạch và thực hiện các phép tính, trong khi thành phần communication dùng cho distributed training. Giao diện Python tập hợp cấu trúc dữ liệu CPP và cung cấp các classes cấp cao bổ sung cho việc train neural network, giúp tiện lợi hơn khi thực hiện các mô hình neural network phức tạp.
Sau đây, chúng tôi giới thiệu cấu trúc phần mềm từ dưới lên.
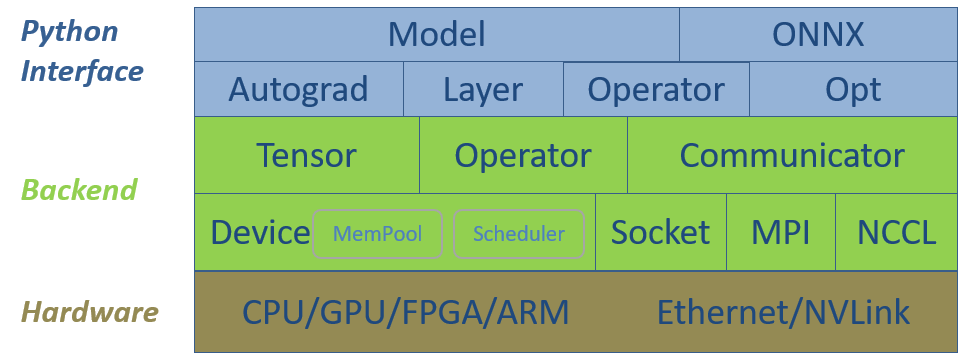
Hình 1 - Cấu trúc
phần mềm SINGA V3.
Backend cấp thấp
Device
Mỗi trường hợp Device, hay thiết bị, được tạo ra từ một thiết bị phần cứng,
v.d GPU hay CPU. Device quản lý bộ nhớ của cấu trúc dữ liệu, và lên kế hoạch
hoạt động cho việc thực hiện, v.d, trên CUDA streams hay CPU threads. Dựa trên
phần cứng và ngôn ngữ lập trình của nó, SINGA sử dụng các loại device cụ thể
sau:
- CudaGPU tượng trưng cho cạc Nvidia GPU. Đơn vị sử dụng là CUDA streams.
- CppCPU là một CPU thông thường. Đơn vị sử dụng là CPU threads.
- OpenclGPU là cạc GPU thông thường cho cả Nvidia và AMD. Đơn vị sử dụng là CommandQueues. Do OpenCL tương thích với rất nhiều thiết bị phần cứng, như FPGA và ARM, OpenclGPU có thể phù hợp với các thiết bị phần cứng khác.
Tensor
Hàm Tensor class là một array đa chiều, lưu trữ biến models, như hình ảnh đầu
vào và bản đồ đặc tính của convolution layer. Mỗi hàm Tensor (v.d một tensor)
được đặt trong một thiết bị, giúp quản lý bộ nhớ của tensor và lên kế hoạch
(phép tính) việc thực hiện với mỗi tensor. Hầu hết phép toán trong machine
learning có thể thể hiện (dày hoặc mỏng) dựa trên nghĩa và việc sử dụng tensor.
Bởi vậy SINGA có thể chạy đa dạng nhiều mô hình, bao gồm deep learning và các mô
hình machine learning truyền thống khác.
Hàm Operator
Có hai dạng hàm operators cho tensors, đại số tuyến tính (linear algebra) như
nhân ma trận (matrix multiplication), và các hàm riêng của neural network như
convolution và pooling. Các hàm đại số tuyến tính được dùng như Tensor
functions và được áp dụng riêng rẽ với các thiết bị phần cứng khác nhau.
- CppMath (tensor_math_cpp.h) thực hiện hoạt động tensor sử dụng Cpp cho CppCPU
- CudaMath (tensor_math_cuda.h) thực hiện hoạt động tensor sử dụng CUDA cho CudaGPU
- OpenclMath (tensor_math_opencl.h) thực hiện hoạt động tensor sử dụng OpenCL cho OpenclGPU
Các toán tử neural network cụ thể cũng được sử dụng riêng rẽ như:
- GpuConvFoward (convolution.h) thực hiện hàm forward function của convolution qua CuDNN trên Nvidia GPU.
- CpuConvForward (convolution.h) thực hiện hàm forward function của convolution qua CPP trên CPU.
Thông thường, người dùng tạo một hàm Device và sử dụng nó để tạo ra các hàm
Tensor. Khi gọi chức năng Tensor hoặc dùng trong neural network, việc thực
hiện tương ứng cho thiết bị sử dụng sẽ được gọi. Nói cách khác, việc áp dụng các
toán tử là rõ ràng với người dùng.
Việc dùng Tensor và Device có thể được áp dụng rộng hơn cho đa dạng thiết bị
phần cứng
sử dụng ngôn ngữ lập trình. Mỗi thiết bị phần cứng mới sẽ được hỗ trợ bằng cách
thêm một Device subclass mới và việc áp dụng tương ứng với các toán tử
operators.
Tối ưu hoá cho tốc độ và bộ nhớ được thực hiện bởi Scheduler và MemPool của
Device. Ví dụ, Scheduler tạo ra một computational graph dựa theo
thư viện chương trình của toán tử operators. Sau đó nó có thể tối ưu lệnh thực
hiện của toán tử trong bộ nhớ chia sẻ và song song.
Communicator
Communicator là để hỗ trợ distributed training. Nó áp dụng
communication protocols sử dụng sockets, MPI và NCCL. Thường người dùng chỉ cần
gọi APIs cấp cao như put() và get() để gửi và nhận tensors. Tối ưu hoá
Communication cho cấu trúc liên kết, kích cỡ tin nhắn, v.v được thực hiện nội
bộ.
Giao diện Python
Tất cả thành phần backend được thể hiện dạng Python modules thông qua SWIG. Thêm vào đó, các classes sau được thêm vào để hỗ trợ việc áp dụng cho các networks phức tạp.
Opt
Opt và các lớp con áp dụng phương pháp (như SGD) để cập nhật các giá trị tham
số model sử dụng tham số gradients. Một lớp con DistOpt đồng bộ
gradients qua các workers trong distributed training bằng cách gọi phương pháp
từ Communicator.
Hàm Operator
Hàm Operator gói nhiều functions khác nhau sử dụng toán tử Tensor hoặc neural
network từ backend. Ví dụ, hàm forward function và backward function ReLU tạo
ra toán tử ReLU operator.
Layer
Layer và các lớp con gói các toán tử operators bằng tham số. Ví dụ,
convolution và linear operators có tham số weight và bias parameters. Tham số
được duy trì bởi các lớp Layer tương ứng.
Autograd
Autograd sử dụng
reverse-mode automatic differentiation
bằng cách ghi nhớ hoạt động của hàm forward functions của các toán tử rồi tự
động gọi hàm backward functions ở chiều ngược lại. Tất cả các hàm functions có
thể được hỗ trợ bởi Scheduler để tạo ra một computational graph
nhằm tối ưu hoá hiệu quả và bộ nhớ.
Model
Model cung cấp giao diện cơ bản để thực hiện các mô hình models mới.
Bạn chỉ cần dùng Model và định nghĩa việc thực hiện forward propagation của
model bằng cách tạo và gọi các layers của toán tử. Model sẽ thực hiện autograd
và tự động cập nhật tham số thông qua Opt trong khi dữ liệu để training được
bơm vào đó. Với Model API, SINGA có nhiều lợi thế trong cả lập trình mệnh lệnh
và lập trình khai báo. Người dùng sử dụng một hệ thống sử dụng Model
API theo dạng lập trình mệnh lệnh như PyTorch. Khác với PyTorch tạo lại phép
thực thi operations ở mỗi vòng lặp, SINGA hỗ trợ phép thực thi qua cách tạo một
computational graph hàm súc (khi tính năng này được sử dụng) sau vòng lặp đầu
tiên. Graph tương tự như đã được tạo bởi các thư viện sử dụng lập trình khai
báo, như TensorFlow. Vì thế, SINGA có thể áp dụng các kĩ thuật tối ưu hoá bộ nhớ
và tốc độ qua computational graph.
ONNX
Để hỗ trợ ONNX, SINGA áp dụng một sonnx module, bao gồm:
- SingaFrontend để lưu SINGA model ở định dạng onnx.
- SingaBackend để tải model định dạng onnx sang SINGA cho training và inference.