
Model
Forward và backward propagation trong mạng thần kinh nhân tạo (neural network) có thể sử dụng một tập hợp các hàm như convolution và pooling. Mỗi hàm nhận một vài input tensors và áp dụng một operator để tạo output tensors. Bằng việc thể hiện mỗi operator là một node và mỗi tensor là một edge, tất cả dạng hàm tạo thành một computational graph. Với computational graph, tối ưu hoá tốc độ và bộ nhớ có thể được tiến hành bởi việc đưa vào thực hiện việc phân bổ/giải phóng bộ nhớ và thao tác một cách hợp lý. Trong SINGA, người dùng chỉ cần xác định neural network model sử dụng API của hàm Model. Graph được xây dựng và tối ưu hoá ở C++ phía sau một cách tự động.
Theo đó, một mặt người dùng thực hiện network sử dụng API của hàm Model tuân theo phong cách lập trình bắt buộc như PyTorch. Có điều khác với PyTorch phải tái tạo lại các thao tác ở mỗi vòng lặp, SINGA buffer các thao tác để tạo computational graph một cách đầy đủ (khi tính năng này được kích hoạt) sau vòng lặp đầu tiên. Do đó, mặt khác, SINGA có computational graph giống như được tạo bởi các libraries sử dụng lập trình khai báo (declarative programming), như TensorFlow. Nên nó được tối ưu hoá qua graph.
Ví Dụ
Mã code sau mô phỏng việc sử dụng API của hàm Model.
- Áp dụng model mới như một tập con của Model class.
class CNN(model.Model):
def __init__(self, num_classes=10, num_channels=1):
super(CNN, self).__init__()
self.conv1 = layer.Conv2d(num_channels, 20, 5, padding=0, activation="RELU")
self.conv2 = layer.Conv2d(20, 50, 5, padding=0, activation="RELU")
self.linear1 = layer.Linear(500)
self.linear2 = layer.Linear(num_classes)
self.pooling1 = layer.MaxPool2d(2, 2, padding=0)
self.pooling2 = layer.MaxPool2d(2, 2, padding=0)
self.relu = layer.ReLU()
self.flatten = layer.Flatten()
self.softmax_cross_entropy = layer.SoftMaxCrossEntropy()
def forward(self, x):
y = self.conv1(x)
y = self.pooling1(y)
y = self.conv2(y)
y = self.pooling2(y)
y = self.flatten(y)
y = self.linear1(y)
y = self.relu(y)
y = self.linear2(y)
return y
def train_one_batch(self, x, y):
out = self.forward(x)
loss = self.softmax_cross_entropy(out, y)
self.optimizer(loss)
return out, loss
- Tạo một instance cho model, optimizer, device, v.v. Compile model đó
model = CNN()
# khởi tạo optimizer và đính nó vào model
sgd = opt.SGD(lr=0.005, momentum=0.9, weight_decay=1e-5)
model.set_optimizer(sgd)
# khởi tạo device
dev = device.create_cuda_gpu()
# input và target placeholders cho model
tx = tensor.Tensor((batch_size, 1, IMG_SIZE, IMG_SIZE), dev, tensor.float32)
ty = tensor.Tensor((batch_size, num_classes), dev, tensor.int32)
# compile model trước khi training
model.compile([tx], is_train=True, use_graph=True, sequential=False)
- Train model theo vòng lặp
for b in range(num_train_batch):
# tạo mini-batch tiếp theo
x, y = ...
# Copy dữ liệu vào input tensors
tx.copy_from_numpy(x)
ty.copy_from_numpy(y)
# Training với một batch
out, loss = model(tx, ty)
Ví dụ này có trên Google Colab notebook tại đây.
Các ví dụ khác:
Thực Hiện
Xây Dựng Graph
SINGA tạo computational graph qua 3 bước:
- Buffer các thao tác
- Phân tích hoạt động các thư viện sử dụng trong dự án (dependencies)
- Tạo nodes và edges dựa trên dependencies
Sử dụng phép nhân ma trận từ dense layer của
MLP model
làm ví dụ. Quá trình này gọi là hàm forward function của class MLP
class MLP(model.Model):
def __init__(self, data_size=10, perceptron_size=100, num_classes=10):
super(MLP, self).__init__()
self.linear1 = layer.Linear(perceptron_size)
...
def forward(self, inputs):
y = self.linear1(inputs)
...
Layer Linear tạo thành từ phép tính mutmul. autograd áp dụng phép matmul
bằng cách gọi hàm Mult được lấy từ CPP qua SWIG.
# áp dụng matmul()
singa.Mult(inputs, w)
Từ phía sau, hàm Mult function được áp dụng bằng cách gọi GEMV, là một hàm
CBLAS. thay vì gọi hàm GEMV trực tiếp, Mult gửi đi GEMV và đối số
(argument) tới thiết bị (device) như sau,
// Áp dụng Mult()
C->device()->Exec(
[a, A, b, B, CRef](Context *ctx) mutable {
GEMV<DType, Lang>(a, A, B, b, &CRef, ctx);
},
read_blocks, {C->block()});
Hàm Exec function của Device buffer hàm này và các đối số của nó. Thêm vào
đó, nó cũng có thông tin về các block (một block là một đoạn bộ nhớ cho một
tensor) để đọc và viết bởi hàm này.
Sau khi Model.forward() được thực hiện xong một lần, tất cả quá trình được
buffer bởi Device. Tiếp theo, thông tin đọc/viết của tất cả quá trình sẽ được
phân tích để tạo computational graph. Ví dụ, nếu một block b được viết bởi quá
trình 01 và sau đó được đọc bởi quá trình 02 khác, chúng ta sẽ biết 02 là dựa
vào 01 và có edge trực tiếp từ A sang B, thể hiện qua block b (hoặc tensor của
nó). Sau đó một graph không tuần hoàn sẽ được tạo ra như dưới đây. Graph chỉ
được tạo ra một lần.
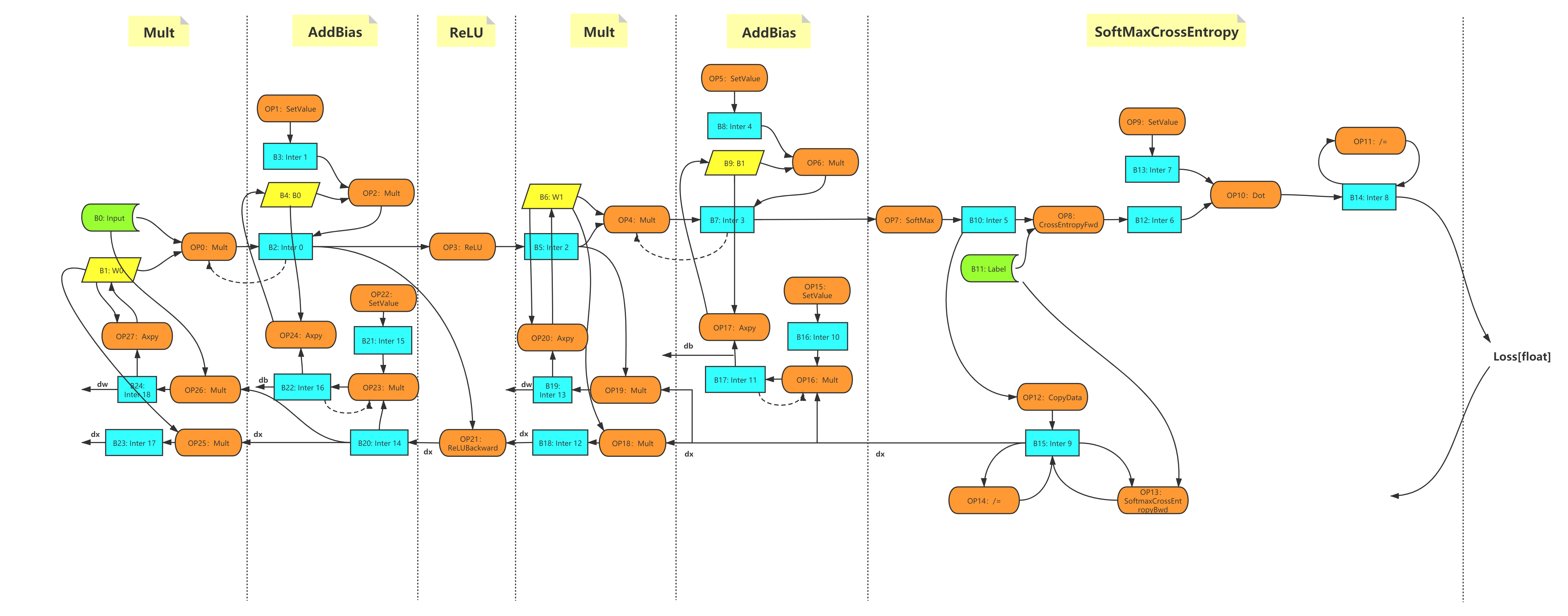
Sơ đồ 1 - Ví dụ Computational graph của MLP.
Tối Ưu Hoá
Hiện nay, các tối ưu hoá sau được thực hiện dựa trên computational graph.
Phân bổ thụ động (Lazy allocation) Khi tensor/blocks được tạo ra, các thiết bị (devices) không phân bổ bộ nhớ cho chúng ngay lập tức. Thay vào đó, khi block được tiếp cận lần đầu tiên, bộ nhớ sẽ được phân bổ.
Tự động tái sử dụng (Automatic recycling) Đếm số của mỗi tensor/block được tính dựa trên graph. Trước khi thực hiện quá trình nào, đếm số là số lượng hàm đọc block này. Trong quá trình thực hiện, khi một hàm nào được tiến hành, đếm số của mỗi block đầu vào bị trừ đi 1. Nếu đếm số của một block bằng 0, thì block này sẽ không được đọc lại nữa trong toàn bộ quá trình còn lại. Bởi vậy, bộ nhớ của nó được giải phóng một cách an toàn. Thêm vào đó, SINGA theo dõi việc sử dụng block bên ngoài graph. Nếu block được sử dụng bởi mã code Python (không phải các hàm autograd), nó sẽ không được tái sử dụng.
Chia sẻ bộ nhớ SINGA sử dụng memory pool, như là
CnMem để quản lý bộ nhớ CUDA. Với Automatic
recycling và memory pool, SINGA có thể chia sẻ bộ nhớ giữa các tensor. Xem xét
hai hàm c = a + b và d=2xc. Trước khi thực hiện hàm thứ hai, theo như Lazy
allocation thì bộ nhớ của d nên được sử dụng. Cũng như a không được sử dụng ở
toàn bộ quá trình còn lại. Theo Tự động sử dụng (Automatic recycling), block của
a sẽ được giải phóng sau hàm đầu tiên. Vì thế, SINGA sẽ đề xuất bốn hàm tới
CUDA stream: addition, free a, malloc b, và multiplication. Memory pool sau
đó có thể chia sẻ bộ nhớ được a với b giải phóng thay vì yêu cầu GPU thực
hiện real malloc cho b.
Các kĩ thuật tối ưu hoá khác, ví dụ từ compliers, như common sub-expression elimination và parallelizing operations trên CUDA streams khác nhau cũng có thể được áp dụng.
Toán Tử (Operator) mới
Mỗi toán tử được định nghĩa trong autograd module áp dụng hai hàm: forward và
backward, được thực hiện bằng cách gọi toán tử (operator) từ backend. Để thêm
một toán tử mới vào hàm autograd, bạn cần thêm nhiều toán tử ở backend.
Lấy toán tử Conv2d làm ví dụ, từ phía Python, hàm forward và backward được thực hiện bằng cách gọi các toán tử từ backend dựa trên loại device.
class _Conv2d(Operation):
def forward(self, x, W, b=None):
......
if training:
if self.handle.bias_term:
self.inputs = (x, W, b) # ghi chép x, W, b
else:
self.inputs = (x, W)
if (type(self.handle) != singa.ConvHandle):
return singa.GpuConvForward(x, W, b, self.handle)
else:
return singa.CpuConvForward(x, W, b, self.handle)
def backward(self, dy):
if (type(self.handle) != singa.ConvHandle):
dx = singa.GpuConvBackwardx(dy, self.inputs[1], self.inputs[0],
self.handle)
dW = singa.GpuConvBackwardW(dy, self.inputs[0], self.inputs[1],
self.handle)
db = singa.GpuConvBackwardb(
dy, self.inputs[2],
self.handle) if self.handle.bias_term else None
else:
dx = singa.CpuConvBackwardx(dy, self.inputs[1], self.inputs[0],
self.handle)
dW = singa.CpuConvBackwardW(dy, self.inputs[0], self.inputs[1],
self.handle)
db = singa.CpuConvBackwardb(
dy, self.inputs[2],
self.handle) if self.handle.bias_term else None
if db:
return dx, dW, db
else:
return dx, dW
Mỗi toán tử ở backend nên được thực hiện theo cách sau:
Giả dụ toán từ là
foo(); khi được thực hiện nên được gói vào trong một hàm khác, như_foo().foo()chuyển_foocùng với các đối số như một hàm lambda tới hàmDevice'sExecđể buffer. Block để đọc và viết cũng được chuyển choExec.Tất cả đối số được sử dụng trong hàm lambda expression cần phải được thu thập dựa trên các nguyên tắc sau.
thu thập bằng giá trị: Nếu biến đối số (argument variable) là biến local hoặc sẽ được giải phóng ngay (như intermediate tensors). Hoặc, những biến số này sẽ bị loại bỏ khifoo()tồn tại.thu thập theo tham khảo:Nếu biến số được ghi lại từ phía python hoặc một biến bất biến (như tham số W và ConvHand trong Conv2d class).mutable: Biểu thức lambda expression nên có biến thẻ (mutable tag) nếu một biến được thu thập theo giá trị bị thay đổi trong hàm_foo()
Đây là một ví dụ về operator được áp dụng ở backend.
Tensor GpuConvBackwardx(const Tensor &dy, const Tensor &W, const Tensor &x,
const CudnnConvHandle &cch) {
CHECK_EQ(dy.device()->lang(), kCuda);
Tensor dx;
dx.ResetLike(x);
dy.device()->Exec(
/*
* dx is a local variable so it's captured by value
* dy is an intermediate tensor and isn't recorded on the python side
* W is an intermediate tensor but it's recorded on the python side
* chh is a variable and it's recorded on the python side
*/
[dx, dy, &W, &cch](Context *ctx) mutable {
Block *wblock = W.block(), *dyblock = dy.block(), *dxblock = dx.block();
float alpha = 1.f, beta = 0.f;
cudnnConvolutionBackwardData(
ctx->cudnn_handle, &alpha, cch.filter_desc, wblock->data(),
cch.y_desc, dyblock->data(), cch.conv_desc, cch.bp_data_alg,
cch.workspace.block()->mutable_data(),
cch.workspace_count * sizeof(float), &beta, cch.x_desc,
dxblock->mutable_data());
},
{dy.block(), W.block()}, {dx.block(), cch.workspace.block()});
/* the lambda expression reads the blocks of tensor dy and w
* and writes the blocks of tensor dx and chh.workspace
*/
return dx;
}
Điểm Chuẩn (Benchmark)
Trên một node
- Thiết lập thí nghiệm
- Kí hiệu
s:giây (second)it: vòng lặp (iteration)Mem:sử dụng bộ nhớ tối đa trong một GPUThroughout:số lượng hình ảnh được xử lý mỗi giâyTime:tổng thời gianSpeed:vòng lặp mỗi giâyReduction:tốc độ giảm bộ nhớ sử dụng so với sử dụng layerSpeedup: tốc độ tăng tốc so với dev branch
- Kết quả
Batchsize Cases Mem(MB) Time(s) Speed(it/s) Throughput Reduction Speedup 16 layer 4975 14.1952 14.0893 225.4285 0.00% 1.0000 model:disable graph 4995 14.1264 14.1579 226.5261 -0.40% 1.0049 model:enable graph, bfs 3283 13.7438 14.5520 232.8318 34.01% 1.0328 model:enable graph, serial 3265 13.7420 14.5540 232.8635 34.37% 1.0330 32 layer 10119 13.4587 7.4302 237.7649 0.00% 1.0000 model:disable graph 10109 13.2952 7.5315 240.6875 0.10% 1.0123 model:enable graph, bfs 6839 13.1059 7.6302 244.1648 32.41% 1.0269 model:enable graph, serial 6845 13.0489 7.6635 245.2312 32.35% 1.0314
Đa quá trình (Multi processes)
- Thiết lập thí nghiệm
- API
- Sử dụng Layer: ResNet50 trong resnet_dist.py
- Sử dụng Model: ResNet50 trong resnet.py
- GPU: NVIDIA RTX 2080Ti * 2
- MPI: hai quá trình MPI trên một node
- API
- Kí hiệu: như trên
- kết quả
Batchsize Cases Mem(MB) Time(s) Speed(it/s) Throughput Reduction Speedup 16 layer 5439 17.3323 11.5391 369.2522 0.00% 1.0000 model:disable graph 5427 17.8232 11.2213 359.0831 0.22% 0.9725 model:enable graph, bfs 3389 18.2310 10.9703 351.0504 37.69% 0.9507 model:enable graph, serial 3437 17.0389 11.7378 375.6103 36.81% 1.0172 32 layer 10547 14.8635 6.7279 430.5858 0.00% 1.0000 model:disable graph 10503 14.7746 6.7684 433.1748 0.42% 1.0060 model:enable graph, bfs 6935 14.8553 6.7316 430.8231 34.25% 1.0006 model:enable graph, serial 7027 14.3271 6.9798 446.7074 33.37% 1.0374
Kết Luận
- Training với computational graph giúp giảm đáng kể khối bộ nhớ.
- Hiện tại, tốc độ có cải thiện một chút. Nhiều tối ưu hoá có thể được thực hiện giúp tăng hiệu quả.