
Benchmark for Distributed Training
Workload: we use a deep convolutional neural network, ResNet-50 as the application. ResNet-50 is has 50 convolution layers for image classification. It requires 3.8 GFLOPs to pass a single image (of size 224x224) through the network. The input image size is 224x224.
Hardware: we use p2.8xlarge instances from AWS, each of which has 8 Nvidia Tesla K80 GPUs, 96 GB GPU memory in total, 32 vCPU, 488 GB main memory, 10 Gbps network bandwidth.
Metric: we measure the time per iteration for different number of workers to evaluate the scalability of SINGA. The batch size is fixed to be 32 per GPU. Synchronous training scheme is applied. As a result, the effective batch size is $32N$, where N is the number of GPUs. We compare with a popular open source system which uses the parameter server topology. The first GPU is selected as the server.
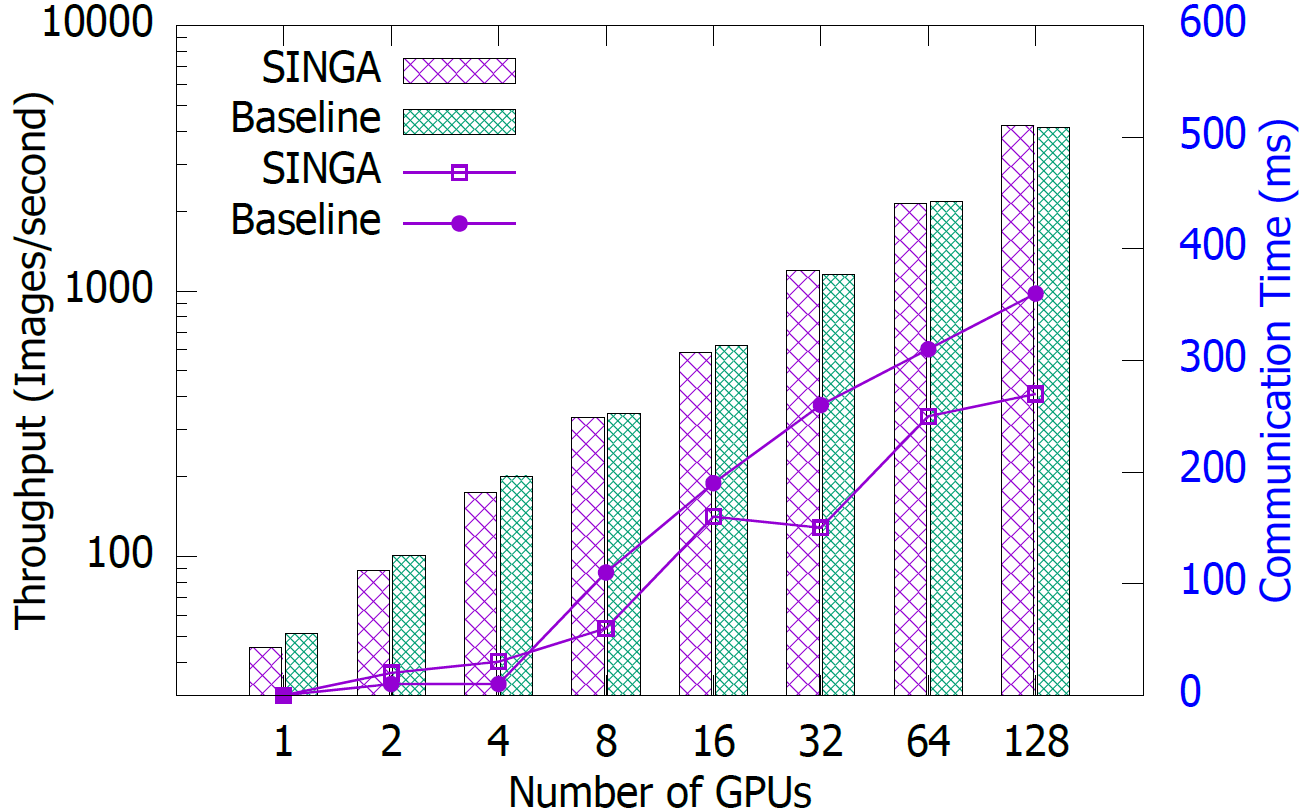
Scalability test. Bars are for the throughput; lines are for the communication cost.