
Distributed Training
SINGA hỗ trợ data parallel training trên nhiều GPUs (trên một node hoặc nhiều node khác nhau). Sơ đồ sau mô phỏng data parallel training:
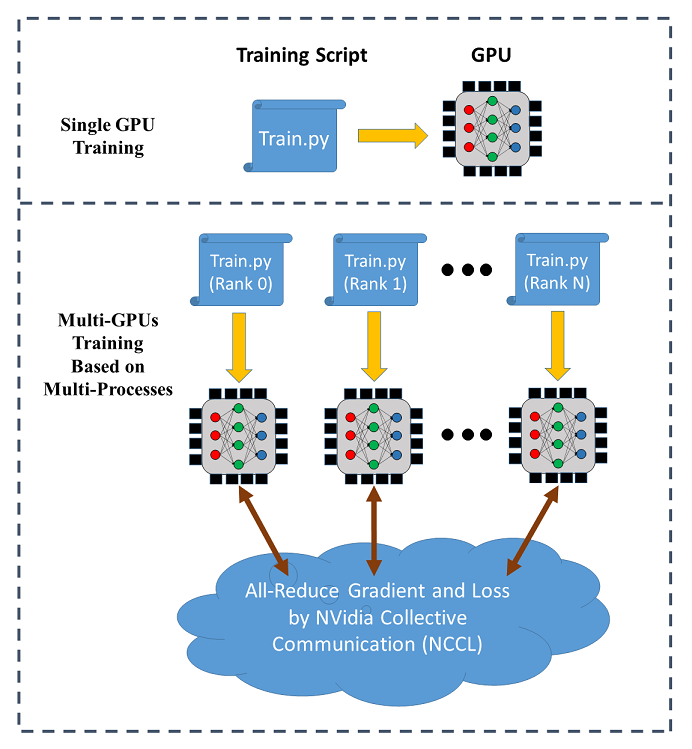
Trong distributed training, mỗi chỉ lệnh (gọi là worker) chạy một training script trên một máy GPU. Mỗi chỉ lệnh (process) có một communication rank riêng. Dữ liệu để training được phân cho các worker và model thì được sao chép cho mỗi worker. Ở mỗi vòng, worker đọc một mini-batch dữ liệu (vd., 256 hình ảnh) từ phần được chia và chạy thuật toán BackPropagation để tính ra độ dốc (gradient) của weight, được lấy trung bình qua all-reduce (cung cấp bởi NCCL) để cập nhật weight theo thuật toán stochastic gradient descent (SGD).
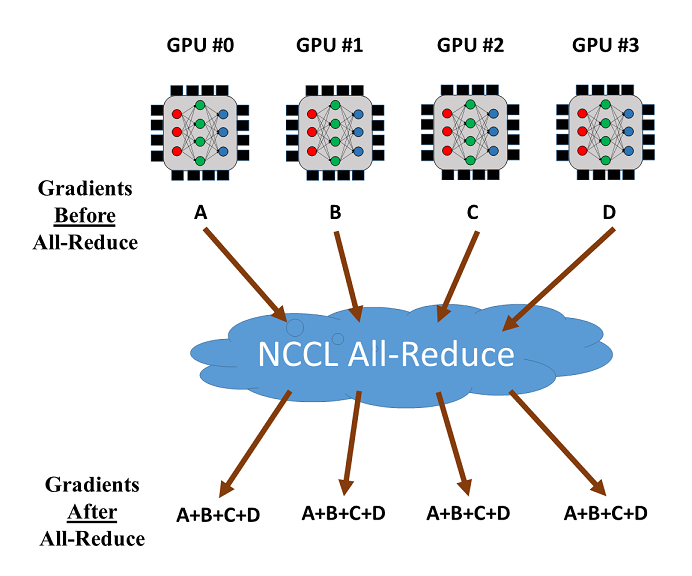
Hàm all-reduce operation bởi NCCL có thể được sử dụng để giảm và đồng bộ hoá độ dốc từ các máy GPU các nhau. Xem thử training với 4 GPUs như dưới đây. Sau khi độ dốc (gradients) từ 4 GPUs được tính, all-reduce sẽ trả lại tổng độ dốc (gradient) cho các GPU và đưa tới mỗi GPU. Sau đó có thể dễ dàng tính ra độ dốc trung bình.
Sử Dụng
SINGA áp dụng một module gọi là DistOpt (là dạng con của Opt) cho
distributed training. Nó gói lại normal SGD optimizer và gọi Communicator để
động bộ hoá độ dốc. Ví dụ sau mô phỏng cách sử dụng DistOpt để training một
CNN model với dữ liệu MNIST. Nguồn code có thể tìm
tại đây, và
Colab notebook.
Code Ví Dụ
- Định nghĩa neural network model:
class CNN(model.Model):
def __init__(self, num_classes=10, num_channels=1):
super(CNN, self).__init__()
self.conv1 = layer.Conv2d(num_channels, 20, 5, padding=0, activation="RELU")
self.conv2 = layer.Conv2d(20, 50, 5, padding=0, activation="RELU")
self.linear1 = layer.Linear(500)
self.linear2 = layer.Linear(num_classes)
self.pooling1 = layer.MaxPool2d(2, 2, padding=0)
self.pooling2 = layer.MaxPool2d(2, 2, padding=0)
self.relu = layer.ReLU()
self.flatten = layer.Flatten()
self.softmax_cross_entropy = layer.SoftMaxCrossEntropy()
def forward(self, x):
y = self.conv1(x)
y = self.pooling1(y)
y = self.conv2(y)
y = self.pooling2(y)
y = self.flatten(y)
y = self.linear1(y)
y = self.relu(y)
y = self.linear2(y)
return y
def train_one_batch(self, x, y, dist_option='fp32', spars=0):
out = self.forward(x)
loss = self.softmax_cross_entropy(out, y)
# cho phép nhiều lựa chọn dùng trong distributed training
# Tham khảo mục "Optimizations về Distributed Training"
if dist_option == 'fp32':
self.optimizer(loss)
elif dist_option == 'fp16':
self.optimizer.backward_and_update_half(loss)
elif dist_option == 'partialUpdate':
self.optimizer.backward_and_partial_update(loss)
elif dist_option == 'sparseTopK':
self.optimizer.backward_and_sparse_update(loss,
topK=True,
spars=spars)
elif dist_option == 'sparseThreshold':
self.optimizer.backward_and_sparse_update(loss,
topK=False,
spars=spars)
return out, loss
# tạo model
model = CNN()
- Tạo
DistOptinstance và đính nó vào model đã tạo:
sgd = opt.SGD(lr=0.005, momentum=0.9, weight_decay=1e-5)
sgd = opt.DistOpt(sgd)
model.set_optimizer(sgd)
dev = device.create_cuda_gpu_on(sgd.local_rank)
Đây là giải thích cho các biến sử dụng trong code:
(i) dev
dev dùng để chỉ Device instance, nơi tải dữ liệu và chạy CNN model.
(ii)local_rank
Local rank chỉ số GPU mà chỉ lệnh (process) hiện tại đang sử dụng trên cùng một
node. Ví dụ, nếu bạn đang sử dụng một node có 2 GPUs, local_rank=0 nghĩa là
chỉ lệnh này đang sử dụng máy GPU đầu tiên, trong khi local_rank=1 nghĩa là
đang sử dụng máy GPU thứ hai. Sử dụng MPI hay đa xử lý, bạn có thể chạy cùng một
tập lệnh training chỉ khác giá trị của local_rank.
(iii)global_rank
Rank trong global biểu thị global rank cho tất cả các chỉ lệnh (process) trong
các nodes mà bạn đang sử dụng. Lấy ví dụ trường hợp bạn có 3 nodes và mỗi một
node có hai GPUs, global_rank=0 nghĩa là chỉ lệnh đang sử dụng máy GPU đầu
tiên ở node đầu tiên, global_rank=2 nghĩa là chỉ lệnh đang sử dụng máy GPU đầu
tiên ở node thứ 2, và global_rank=4 nghĩa là chỉ lệnh đang sử dụng máy GPU đầu
tiên ở node thứ 3.
- Tải và phân chia dữ liệu để training/validation
def data_partition(dataset_x, dataset_y, global_rank, world_size):
data_per_rank = dataset_x.shape[0] // world_size
idx_start = global_rank * data_per_rank
idx_end = (global_rank + 1) * data_per_rank
return dataset_x[idx_start:idx_end], dataset_y[idx_start:idx_end]
train_x, train_y, test_x, test_y = load_dataset()
train_x, train_y = data_partition(train_x, train_y,
sgd.global_rank, sgd.world_size)
test_x, test_y = data_partition(test_x, test_y,
sgd.global_rank, sgd.world_size)
Một phần của bộ dữ liệu (dataset) được trả lại cho dev.
Tại đây, world_size thể hiện tổng số chỉ lệnh trong tất cả các node mà bạn
đang sử dụng cho distributed training.
- Khởi tạo và đồng bộ các tham số của model cho tất cả workers:
# Đồng bộ tham số ban đầu
tx = tensor.Tensor((batch_size, 1, IMG_SIZE, IMG_SIZE), dev, tensor.float32)
ty = tensor.Tensor((batch_size, num_classes), dev, tensor.int32)
model.compile([tx], is_train=True, use_graph=graph, sequential=True)
...
# Sử dụng cùng một random seed cho các ranks khác nhau
seed = 0
dev.SetRandSeed(seed)
np.random.seed(seed)
- Chạy BackPropagation và distributed SGD
for epoch in range(max_epoch):
for b in range(num_train_batch):
x = train_x[idx[b * batch_size: (b + 1) * batch_size]]
y = train_y[idx[b * batch_size: (b + 1) * batch_size]]
tx.copy_from_numpy(x)
ty.copy_from_numpy(y)
# Train the model
out, loss = model(tx, ty)
Hướng Dẫn Thực Hiện
Có hai cách để bắt đầu quá trình training: MPI hoặc Python đa xử lý.
Python Đa Xử Lý
Chạy trên một node với nhiều GPUs, trong đó mỗi GPU là một worker.
- Đặt tất cả các training codes trong cùng một hàm (function)
def train_mnist_cnn(nccl_id=None, local_rank=None, world_size=None):
...
- Tạo
mnist_multiprocess.py
if __name__ == '__main__':
# Generate a NCCL ID to be used for collective communication
nccl_id = singa.NcclIdHolder()
# Define the number of GPUs to be used in the training process
world_size = int(sys.argv[1])
# Define and launch the multi-processing
import multiprocessing
process = []
for local_rank in range(0, world_size):
process.append(multiprocessing.Process(target=train_mnist_cnn,
args=(nccl_id, local_rank, world_size)))
for p in process:
p.start()
Dưới đây là giải thích cho các biến tạo ở trên:
(i) nccl_id
Lưu ý rằng chúng ta cần phải tạo một NCCL ID ở đây để sử dụng cho collective communication, sau đó gửi nó tới tất cả các chỉ lệnh. NCCL ID giống như là vé vào cửa, khi chỉ có chỉ lệnh với ID này có thể tham gia vào quá trình all-reduce. (Về sua nếu dùng MPI, thì việc sử dụng NCCL ID là không cần thiết, bởi vì ID được gửi đi bởi MPI trong code của chúng tôi một cách tự động)
(ii) world_size
world_size là số lượng máy GPUs bạn muốn sử dụng cho training.
(iii) local_rank
local_rank xác định local rank của distributed training và máy gpu được sử dụng trong chỉ lệnh. Trong code bên trên, for loop được sử dụng để chạy hàm train function, và local_rank chạy vòng từ 0 tới world_size. Trong trường hợp này, chỉ lệnh khác nhau có thể sử dụng máy GPUs khác nhau để training.
Tham số để tạo DistOpt instance cần được cập nhật như sau:
sgd = opt.DistOpt(sgd, nccl_id=nccl_id, local_rank=local_rank, world_size=world_size)
- Chạy
mnist_multiprocess.py
python mnist_multiprocess.py 2
Kết qủa hiển thị tốc độ so với training trên một máy GPU.
Starting Epoch 0:
Training loss = 408.909790, training accuracy = 0.880475
Evaluation accuracy = 0.956430
Starting Epoch 1:
Training loss = 102.396790, training accuracy = 0.967415
Evaluation accuracy = 0.977564
Starting Epoch 2:
Training loss = 69.217010, training accuracy = 0.977915
Evaluation accuracy = 0.981370
Starting Epoch 3:
Training loss = 54.248390, training accuracy = 0.982823
Evaluation accuracy = 0.984075
Starting Epoch 4:
Training loss = 45.213406, training accuracy = 0.985560
Evaluation accuracy = 0.985276
Starting Epoch 5:
Training loss = 38.868435, training accuracy = 0.987764
Evaluation accuracy = 0.986278
Starting Epoch 6:
Training loss = 34.078186, training accuracy = 0.989149
Evaluation accuracy = 0.987881
Starting Epoch 7:
Training loss = 30.138697, training accuracy = 0.990451
Evaluation accuracy = 0.988181
Starting Epoch 8:
Training loss = 26.854443, training accuracy = 0.991520
Evaluation accuracy = 0.988682
Starting Epoch 9:
Training loss = 24.039650, training accuracy = 0.992405
Evaluation accuracy = 0.989083
MPI
Có thể dùng cho cả một node và nhiều node miễn là có nhiều máy GPUs.
- Tạo
mnist_dist.py
if __name__ == '__main__':
train_mnist_cnn()
- Tạo một hostfile cho MPI, vd. hostfile dưới đây sử dụng 2 chỉ lệnh (vd., 2 GPUs) trên một node
localhost:2
- Khởi động quá trình training qua
mpiexec
mpiexec --hostfile host_file python mnist_dist.py
Kết qủa có thể hiển thị tốc độ so với training trên một máy GPU.
Starting Epoch 0:
Training loss = 383.969543, training accuracy = 0.886402
Evaluation accuracy = 0.954327
Starting Epoch 1:
Training loss = 97.531479, training accuracy = 0.969451
Evaluation accuracy = 0.977163
Starting Epoch 2:
Training loss = 67.166870, training accuracy = 0.978516
Evaluation accuracy = 0.980769
Starting Epoch 3:
Training loss = 53.369656, training accuracy = 0.983040
Evaluation accuracy = 0.983974
Starting Epoch 4:
Training loss = 45.100403, training accuracy = 0.985777
Evaluation accuracy = 0.986078
Starting Epoch 5:
Training loss = 39.330826, training accuracy = 0.987447
Evaluation accuracy = 0.987179
Starting Epoch 6:
Training loss = 34.655270, training accuracy = 0.988799
Evaluation accuracy = 0.987780
Starting Epoch 7:
Training loss = 30.749735, training accuracy = 0.989984
Evaluation accuracy = 0.988281
Starting Epoch 8:
Training loss = 27.422146, training accuracy = 0.991319
Evaluation accuracy = 0.988582
Starting Epoch 9:
Training loss = 24.548153, training accuracy = 0.992171
Evaluation accuracy = 0.988682
Tối Ưu Hoá Distributed Training
SINGA cung cấp chiến lược đa tối ưu hoá cho distributed training để giảm
communication cost. Tham khảo API của DistOpt cho cấu hình của mỗi cách.
Khi sử dụng model.Model để tạo một model, cần phải đặt các lựa chọn cho
distributed training trong phương pháp train_one_batch. Tham khảo code ví dụ
trên đầu trang. Bạn có thể chỉ cần copy code cho các lựa chọn và sử dụng nó cho
các model khác. Với các lựa chọn xác định, ta có thể đặt tham sốdist_option và
spars khi bắt đầu training với model(tx, ty, dist_option, spars)
Không Tối Ưu Hoá
out, loss = model(tx, ty)
loss là output tensor từ hàm loss function, vd., cross-entropy cho
classification tasks.
Half-precision Gradients
out, loss = model(tx, ty, dist_option = 'fp16')
Chuyển đổi gía trị độ dốc sang hiển thị dạng 16-bit (vd., half-precision) trước khi gọi hàm all-reduce.
Đồng Bộ Cục Bộ (Partial Synchronization)
out, loss = model(tx, ty, dist_option = 'partialUpdate')
Ở mỗi vòng lặp (iteration), mỗi rank thực hiện việc cập nhật sgd. Sau đó chỉ một
nhóm tham số là được tính trung bình để đồng bộ hoá. Điều này giúp tiết kiệm
communication cost. Độ lớn của nhóm này được xác định khi tạo hàm DistOpt
instance.
Phân Bổ Độ Dốc (Gradient Sparsification)
Kế hoạch phân bổ để chọn ra một nhóm nhỏ độ dốc nhằm thực hiện all-reduce. Có hai cách:
- Chọn K phần tử lớn nhất. spars là một phần (0 - 1) của tổng số phần tử được chọn.
out, loss = model(tx, ty, dist_option = 'sparseTopK', spars = spars)
- Tất cả độ dốc có giá trị tuyệt đối lớn hơn ngưỡng spars đặt trước được lựa chọn.
out, loss = model(tx, ty, dist_option = 'sparseThreshold', spars = spars)
Các hyper-parameter được cấu tạo khi tạo hàm DistOpt instance.
Thực Hiện
Mục này chủ yếu dành cho các lập trình viên (developer) muốn biết lập trình trong distribute module được thực hiện như thế nào.
Giao Diện C cho Bộ Chuyển Mạch (communicator) NCCL
Trước tiên, communication layer được lập trình bằng ngôn ngữ C communicator.cc. Nó áp dụng NCCL library cho collective communication.
Có hai hàm tạo nên communicator, một cho MPI và một cho đa phương thức (multiprocess).
(i) Hàm tạo sử dụng MPI
Hàm tạo bước đầu sẽ sử dụng global rank và world size, sau đó tính toán ra local rank. Tiếp theo, rank 0 sẽ tạo ra NCCL ID và phát nó lên mỗi rank. Sau đó, nó gọi hàm setup để khởi tạo NCCL communicator, cuda streams, và buffers.
(ii) Hàm tạo sử dụng Python đa phương thức
Hàm tạo bước đầu sẽ sử dụng rank, world size, và NCCL ID từ input argument. Sau đó, nó gọi hàm setup function để khởi tạo NCCL communicator, cuda streams, và buffers.
Sau khi khởi động, nó thực hiện chức năng all-reduce để đồng bộ hoá các tham số model và độ dốc. Ví dụ, synch sử dụng một input tensor và tiến hành all-reduce qua đoạn chương trình NCCL. Sau khi gọi synch, cần gọi hàm wait để đợi hàm all-reduce operation kết thúc.
Giao Diện Python của DistOpt
Sau đó, giao diện python sẽ tạo ra một DistOpt class để gói một optimizer object để thực hiện distributed training dựa trên MPI hoặc đa xử lý. Trong khi khởi động, nó tạo ra một NCCL communicator object (từ giao diện C đề cập ở mục nhỏ phía trên). Sau đó, communicator object này được sử dụng trong mỗi hàm all-reduce trong DistOpt.
Trong MPI hoặc đa xử lý, mỗi chỉ lệnh có một rank, cho biết thông tin máy GPU nào qui trình này đang sử dụng. Dữ liệu training được chia nhỏ để mỗi chỉ lệnh có thể đánh giá sub-gradient dựa trên dữ liệu đã chia trước đó. Sau khi sub-gradient được tạo ra ở mỗi chỉ lệnh, độ dốc stochastic gradient tổng hợp sẽ được tạo ra bằng cách all-reduce các sub-gradients đánh giá bởi tất cả các chỉ lệnh.