
Distributed Training
SINGA支持跨多个GPU的数据并行训练(在单个节点上或跨不同节点)。下图说明了数据并行训练的情况:
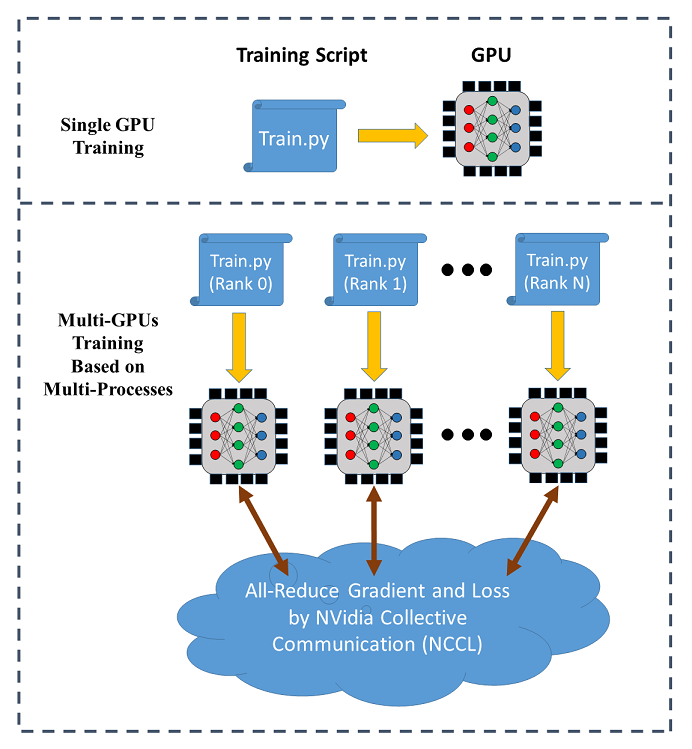
在分布式训练中,每个进程(称为worker)在单个GPU上运行一个训练脚本,每个进程都有一个单独的通信等级,训练数据被分发给各个worker,模型在每个worker上被复制。在每次迭代中,worker从其分区中读取数据的一个mini-batch(例如,256张图像),并运行BackPropagation算法来计算权重的梯度,通过all-reduce(由NCCL提供)进行平均,按照随机梯度下降算法(SGD)进行权重更新。
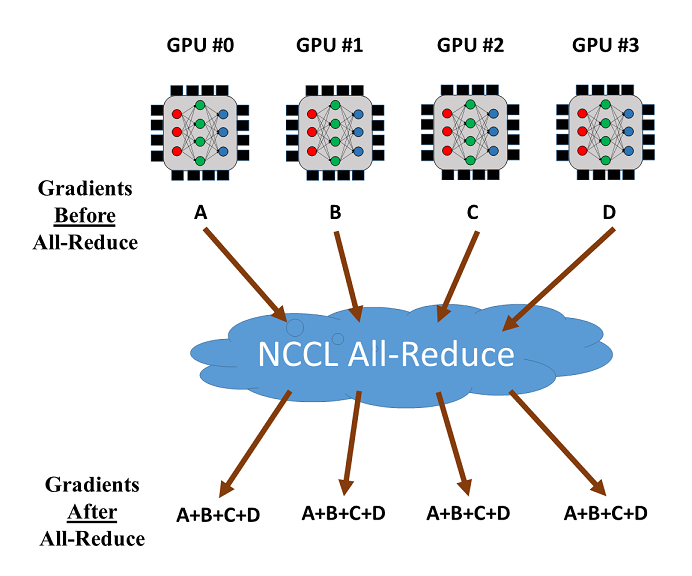
NCCL的all-reduce操作可以用来减少和同步不同GPU的梯度。假设我们使用4个GPU进行训练,如下图所示。一旦计算出4个GPU的梯度,all-reduce将返回GPU的梯度之和,并使其在每个GPU上可用,然后就可以轻松计算出平均梯度。
使用
SINGA提供了一个名为DistOpt(Opt的一个子类)的模块,用于分布式训练。它封装了一个普通的SGD优化器,并调用Communicator进行梯度同步。下面的例子说明了如何使用DistOpt在MNIST数据集上训练一个CNN模型。源代码在这里,或者可以使用Colab notebook。
代码示例
- 定义神经网络模型:
class CNN(model.Model):
def __init__(self, num_classes=10, num_channels=1):
super(CNN, self).__init__()
self.conv1 = layer.Conv2d(num_channels, 20, 5, padding=0, activation="RELU")
self.conv2 = layer.Conv2d(20, 50, 5, padding=0, activation="RELU")
self.linear1 = layer.Linear(500)
self.linear2 = layer.Linear(num_classes)
self.pooling1 = layer.MaxPool2d(2, 2, padding=0)
self.pooling2 = layer.MaxPool2d(2, 2, padding=0)
self.relu = layer.ReLU()
self.flatten = layer.Flatten()
self.softmax_cross_entropy = layer.SoftMaxCrossEntropy()
def forward(self, x):
y = self.conv1(x)
y = self.pooling1(y)
y = self.conv2(y)
y = self.pooling2(y)
y = self.flatten(y)
y = self.linear1(y)
y = self.relu(y)
y = self.linear2(y)
return y
def train_one_batch(self, x, y, dist_option='fp32', spars=0):
out = self.forward(x)
loss = self.softmax_cross_entropy(out, y)
# Allow different options for distributed training
# See the section "Optimizations for Distributed Training"
if dist_option == 'fp32':
self.optimizer(loss)
elif dist_option == 'fp16':
self.optimizer.backward_and_update_half(loss)
elif dist_option == 'partialUpdate':
self.optimizer.backward_and_partial_update(loss)
elif dist_option == 'sparseTopK':
self.optimizer.backward_and_sparse_update(loss,
topK=True,
spars=spars)
elif dist_option == 'sparseThreshold':
self.optimizer.backward_and_sparse_update(loss,
topK=False,
spars=spars)
return out, loss
# create model
model = CNN()
- 创建
DistOpt实例并将其应用到创建的模型上:
sgd = opt.SGD(lr=0.005, momentum=0.9, weight_decay=1e-5)
sgd = opt.DistOpt(sgd)
model.set_optimizer(sgd)
dev = device.create_cuda_gpu_on(sgd.local_rank)
下面是关于代码中一些变量的解释:
(i) dev
dev代表Device实例,在设备中加载数据并运行CNN模型。
(ii)local_rank
Local rank表示当前进程在同一节点中使用的GPU数量。例如,如果你使用的节点有2个GPU,local_rank=0表示这个进程使用的是第一个GPU,而local_rank=1表示使用的是第二个GPU。使用MPI或多进程,你能够运行相同的训练脚本,唯一的区别local_rank的值不同。
(iii)global_rank
global中的rank代表了你使用的所有节点中所有进程的全局排名。让我们考虑这样的情况:你有3个节点,每个节点有两个GPU, global_rank=0表示使用第1个节点的第1个GPU的进程, global_rank=2表示使用第2个节点的第1个GPU的进程, global_rank=4表示使用第3个节点的第1个GPU的进程。
- 加载和分割训练/验证数据:
def data_partition(dataset_x, dataset_y, global_rank, world_size):
data_per_rank = dataset_x.shape[0] // world_size
idx_start = global_rank * data_per_rank
idx_end = (global_rank + 1) * data_per_rank
return dataset_x[idx_start:idx_end], dataset_y[idx_start:idx_end]
train_x, train_y, test_x, test_y = load_dataset()
train_x, train_y = data_partition(train_x, train_y,
sgd.global_rank, sgd.world_size)
test_x, test_y = data_partition(test_x, test_y,
sgd.global_rank, sgd.world_size)
这个dev的数据集的一个分区被返回。
这里,world_size代表你用于分布式训练的所有节点中的进程总数。
- 初始化并同步所有worker的模型参数:
#Synchronize the initial parameter
tx = tensor.Tensor((batch_size, 1, IMG_SIZE, IMG_SIZE), dev, tensor.float32)
ty = tensor.Tensor((batch_size, num_classes), dev, tensor.int32)
model.compile([tx], is_train=True, use_graph=graph, sequential=True)
...
#Use the same random seed for different ranks
seed = 0
dev.SetRandSeed(seed)
np.random.seed(seed)
- 运行BackPropagation和分布式SGD
for epoch in range(max_epoch):
for b in range(num_train_batch):
x = train_x[idx[b * batch_size: (b + 1) * batch_size]]
y = train_y[idx[b * batch_size: (b + 1) * batch_size]]
tx.copy_from_numpy(x)
ty.copy_from_numpy(y)
# Train the model
out, loss = model(tx, ty)
执行命令
有两种方式可以启动训练,MPI或Python multiprocessing。
Python multiprocessing
它可以在一个节点上使用多个GPU,其中,每个GPU是一个worker。
- 将上述训练用的代码打包进一个函数:
def train_mnist_cnn(nccl_id=None, local_rank=None, world_size=None):
...
- 创建
mnist_multiprocess.py。
if __name__ == '__main__':
# Generate a NCCL ID to be used for collective communication
nccl_id = singa.NcclIdHolder()
# Define the number of GPUs to be used in the training process
world_size = int(sys.argv[1])
# Define and launch the multi-processing
import multiprocessing
process = []
for local_rank in range(0, world_size):
process.append(multiprocessing.Process(target=train_mnist_cnn,
args=(nccl_id, local_rank, world_size)))
for p in process:
p.start()
下面是关于上面所创建的变量的一些说明:
(i) nccl_id
需要注意的是,我们在这里需要生成一个NCCL ID,用于集体通信,然后将其传递给所有进程。NCCL ID就像一个门票,只有拥有这个ID的进程才能加入到all-reduce操作中。(如果我们接下来使用MPI,NCCL ID的传递就没有必要了,因为在我们的代码中,这个ID会由MPI自动广播。)
(ii) world_size
world_size是您想用于训练的GPU数量。
(iii) local_rank
local_rank决定分布式训练的本地顺序,以及在训练过程中使用哪个gpu。在上面的代码中,我们使用for循环来运行训练函数,其中参数local_rank从0迭代到world_size。在这种情况下,不同的进程可以使用不同的GPU进行训练。
创建DistOpt实例的参数应按照如下方式更新:
sgd = opt.DistOpt(sgd, nccl_id=nccl_id, local_rank=local_rank, world_size=world_size)
- 运行
mnist_multiprocess.py:
python mnist_multiprocess.py 2
与单GPU训练相比,它最主要的意义是速度提升:
Starting Epoch 0:
Training loss = 408.909790, training accuracy = 0.880475
Evaluation accuracy = 0.956430
Starting Epoch 1:
Training loss = 102.396790, training accuracy = 0.967415
Evaluation accuracy = 0.977564
Starting Epoch 2:
Training loss = 69.217010, training accuracy = 0.977915
Evaluation accuracy = 0.981370
Starting Epoch 3:
Training loss = 54.248390, training accuracy = 0.982823
Evaluation accuracy = 0.984075
Starting Epoch 4:
Training loss = 45.213406, training accuracy = 0.985560
Evaluation accuracy = 0.985276
Starting Epoch 5:
Training loss = 38.868435, training accuracy = 0.987764
Evaluation accuracy = 0.986278
Starting Epoch 6:
Training loss = 34.078186, training accuracy = 0.989149
Evaluation accuracy = 0.987881
Starting Epoch 7:
Training loss = 30.138697, training accuracy = 0.990451
Evaluation accuracy = 0.988181
Starting Epoch 8:
Training loss = 26.854443, training accuracy = 0.991520
Evaluation accuracy = 0.988682
Starting Epoch 9:
Training loss = 24.039650, training accuracy = 0.992405
Evaluation accuracy = 0.989083
MPI
只要有多个GPU,MPI既适用于单节点,也适用于多节点。
- 创建
mnist_dist.py。
if __name__ == '__main__':
train_mnist_cnn()
- 为MPI生成一个hostfile,例如下面的hostfile在一个节点上使用了2个进程(即2个GPU):
localhost:2
- 通过
mpiexec启动训练:
mpiexec --hostfile host_file python mnist_dist.py
与单GPU训练相比,它同样可以带来速度的提升:
Starting Epoch 0:
Training loss = 383.969543, training accuracy = 0.886402
Evaluation accuracy = 0.954327
Starting Epoch 1:
Training loss = 97.531479, training accuracy = 0.969451
Evaluation accuracy = 0.977163
Starting Epoch 2:
Training loss = 67.166870, training accuracy = 0.978516
Evaluation accuracy = 0.980769
Starting Epoch 3:
Training loss = 53.369656, training accuracy = 0.983040
Evaluation accuracy = 0.983974
Starting Epoch 4:
Training loss = 45.100403, training accuracy = 0.985777
Evaluation accuracy = 0.986078
Starting Epoch 5:
Training loss = 39.330826, training accuracy = 0.987447
Evaluation accuracy = 0.987179
Starting Epoch 6:
Training loss = 34.655270, training accuracy = 0.988799
Evaluation accuracy = 0.987780
Starting Epoch 7:
Training loss = 30.749735, training accuracy = 0.989984
Evaluation accuracy = 0.988281
Starting Epoch 8:
Training loss = 27.422146, training accuracy = 0.991319
Evaluation accuracy = 0.988582
Starting Epoch 9:
Training loss = 24.548153, training accuracy = 0.992171
Evaluation accuracy = 0.988682
针对分布式训练的优化
SINGA为分布式训练提供了多种优化策略,以降低模块间的通信成本。参考DistOpt的API,了解每种策略的配置。
当我们使用model.Model建立模型时,我们需要在training_one_batch方法中启用分布式训练的选项,请参考本页顶部的示例代码。我们也可以直接复制这些选项的代码,然后在其他模型中使用。
有了定义的选项,我们可以在使用model(tx, ty, dist_option, spars)开始训练时,设置对应的参数dist_option和spars。
不采取优化手段
out, loss = model(tx, ty)
loss是损失函数的输出张量,例如分类任务中的交叉熵。
半精度梯度(Half-precision Gradients)
out, loss = model(tx, ty, dist_option = 'fp16')
在调用all-reduce之前,它将每个梯度值转换为16-bit表示(即半精度)。
部分同步(Partial Synchronization)
out, loss = model(tx, ty, dist_option = 'partialUpdate')
在每一次迭代中,每个rank都做本地SGD更新。然后,只对一个部分的参数进行平均同步,从而节省了通信成本。分块大小是在创建DistOpt实例时配置的。
梯度稀疏化(Gradient Sparsification)
该策略应用稀疏化方案来选择梯度的子集进行all-reduce,有两种方式:
- 选择前k大的元素,spars是被选择的元素的一部分(比例在0 - 1之间)。
out, loss = model(tx, ty, dist_option = 'sparseTopK', spars = spars)
- 所有绝对值大于预定义阈值的梯度都会被选中。
out, loss = model(tx, ty, dist_option = 'sparseThreshold', spars = spars)
超参数在创建DistOpt实例时配置。
实现
本节主要是让开发者了解分布训练模块的代码是如何实现的。
NCCL communicator的C接口
首先,通信层是用C语言communicator.cc编写的,它调用用NCCL库进行集体通信。
communicator有两个构造器,一个是MPI的,另一个是Multiprocess的。
(i) MPI构造器
构造器首先先获取全局rank和world_size,计算出本地rank,然后由rank 0生成NCCL ID并广播给每个rank。之后,它调用setup函数来初始化NCCL communicator、cuda流和缓冲区。
(ii) Python multiprocess构造器
构造器首先从输入参数中获取rank、world_size和NCCL ID。之后,调用setup函数来初始化NCCL communicator、cuda流和缓冲区。
在初始化之后,它提供了all-reduce功能来同步模型参数或梯度。例如,synch接收一个输入张量,通过NCCL例程进行all-reduce,在我们调用synch之后,需要调用wait函数来等待all-reduce操作的完成。
DistOpt的Python接口
然后,python接口提供了一个DistOpt类来封装一个optimizer对象,以执行基于MPI或Multiprocess的分布式训练。在初始化过程中,它创建了一个NCCL communicator对象(来自于上面小节提到的C接口),然后,DistOpt中的每一次all-reduce操作都会用到这个communicator对象。
在MPI或Multiprocess中,每个进程都有一个独立的rank,它给出了各个进程使用的GPU的信息。训练数据是被拆分的,因此每个进程可以根据一部分训练数据来评估子梯度。一旦每个进程的子梯度被计算出来,就可以将所有进程计算出的子梯度做all-reduce,得到总体随机梯度。