
Software Stack
SINGA's software stack includes two major levels, the low level backend classes and the Python interface level. Figure 1 illustrates them together with the hardware. The backend components provide basic data structures for deep learning models, hardware abstractions for scheduling and executing operations, and communication components for distributed training. The Python interface wraps some CPP data structures and provides additional high-level classes for neural network training, which makes it convenient to implement complex neural network models.
Next, we introduce the software stack in a bottom-up manner.
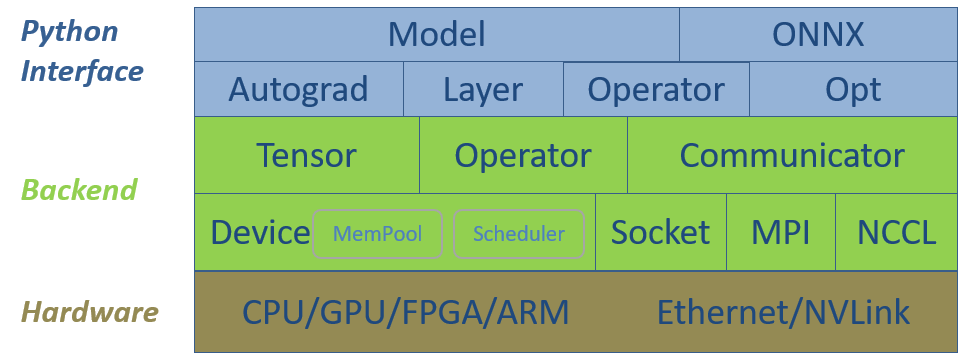
Figure 1 - SINGA V3
software stack.
Low-level Backend
Device
Each Device instance, i.e., a device, is created against one hardware device,
e.g. a GPU or a CPU. Device manages the memory of the data structures, and
schedules the operations for executing, e.g., on CUDA streams or CPU threads.
Depending on the hardware and its programming language, SINGA have implemented
the following specific device classes:
- CudaGPU represents an Nvidia GPU card. The execution units are the CUDA streams.
- CppCPU represents a normal CPU. The execution units are the CPU threads.
- OpenclGPU represents normal GPU card from both Nvidia and AMD. The execution units are the CommandQueues. Given that OpenCL is compatible with many hardware devices, e.g. FPGA and ARM, the OpenclGPU has the potential to be extended for other devices.
Tensor
Tensor class represents a multi-dimensional array, which stores model
variables, e.g., the input images and feature maps from the convolution layer.
Each Tensor instance (i.e. a tensor) is allocated on a device, which manages
the memory of the tensor and schedules the (computation) operations against
tensors. Most machine learning algorithms could be expressed using (dense or
sparse) the tensor abstraction and its operations. Therefore, SINGA would be
able to run a wide range of models, including deep learning models and other
traditional machine learning models.
Operator
There are two types of operators against tensors, linear algebra operators like
matrix multiplication, and neural network specific operators like convolution
and pooling. The linear algebra operators are provided as Tensor functions and
are implemented separately for different hardware devices
- CppMath (tensor_math_cpp.h) implements the tensor operations using Cpp for CppCPU
- CudaMath (tensor_math_cuda.h) implements the tensor operations using CUDA for CudaGPU
- OpenclMath (tensor_math_opencl.h) implements the tensor operations using OpenCL for OpenclGPU
The neural network specific operators are also implemented separately, e.g.,
- GpuConvFoward (convolution.h) implements the forward function of convolution via CuDNN on Nvidia GPU.
- CpuConvForward (convolution.h) implements the forward function of convolution using CPP on CPU.
Typically, users create a Device instance and use it to create multiple
Tensor instances. When users call the Tensor functions or neural network
operations, the corresponding implementation for the resident device will be
invoked. In other words, the implementation of operators is transparent to
users.
The Tensor and Device abstractions are extensible to support a wide range of hardware device using different programming languages. A new hardware device would be supported by adding a new Device subclass and the corresponding implementation of the operators.
Optimizations in terms of speed and memory are done by the Scheduler and
MemPool of the Device. For example, the Scheduler creates a
computational graph according to the dependency of the operators.
Then it can optimize the execution order of the operators for parallelism and
memory sharing.
Communicator
Communicator is to support distributed training. It implements
the communication protocols using sockets, MPI and NCCL. Typically users only
need to call the high-level APIs like put() and get() for sending and
receiving tensors. Communication optimization for the topology, message size,
etc. is done internally.
Python Interface
All the backend components are exposed as Python modules via SWIG. In addition, the following classes are added to support the implementation of complex neural networks.
Opt
Opt and its subclasses implement the methods (such as SGD) for updating model
parameter values using parameter gradients. A subclass DistOpt
synchronizes the gradients across the workers for distributed training by
calling methods from Communicator.
Operator
Operator wraps multiple functions implemented using the Tensor or neural
network operators from the backend. For example, the forward function and
backward function ReLU compose the ReLU operator.
Layer
Layer and its subclasses wraps the operators with parameters. For instance,
convolution and linear operators
have weight and bias parameters. The parameters are maintained by the
corresponding Layer class.
Autograd
Autograd implements the
reverse-mode automatic differentiation
by recording the execution of the forward functions of the operators calling the
backward functions automatically in the reverse order. All functions can be
buffered by the Scheduler to create a computational graph for
efficiency and memory optimization.
Model
Model provides an easy interface to implement new network models. You
just need to inherit Model and define the forward propagation of the model by
creating and calling the layers or operators. Model will do autograd and
update the parameters via Opt automatically when training data is fed into it.
With the Model API, SINGA enjoys the advantages of imperative programming and
declarative programming. Users implement a network using the Model
API following the imperative programming style like PyTorch. Different from
PyTorch which recreates the operations in every iteration, SINGA buffers the
operations to create a computational graph implicitly (when this feature is
enabled) after the first iteration. The graph is similar to that created by
libraries using declarative programming, e.g., TensorFlow. Therefore, SINGA can
apply the memory and speed optimization techniques over the computational graph.
ONNX
To support ONNX, SINGA implements a sonnx module, which includes:
- SingaFrontend for saving SINGA model into onnx format.
- SingaBackend for loading onnx format model into SINGA for training and inference.