
Benchmark for Distributed Training
项目:我们使用深度卷积神经网 络ResNet-50。 它有 50 个卷积层,用于图像分类。它需要 3.8 个 GFLOPs 来通过网络处理一张图像(尺 寸为 224x224)。输入的图像大小为 224x224。
硬件方面:我们使用的是 AWS 的 p2.8xlarge 实例,每个实例有 8 个 Nvidia Tesla K80 GPU,共 96GB GPU 内存,32 个 vCPU,488GB 主内存,10Gbps 网络带宽。
衡量标准:我们衡量不同数量 worker 的每次迭代时间,以评估 SINGA 的可扩展性
。Batch-size 固定为每个 GPU32 个。采用同步训练方案。因此,有效的 batch-size
是32N,其中 N 是 GPU 的数量。我们与一个流行的开源系统进行比较,该系统采用参数
服务器拓扑结构。选择第一个 GPU 作为服务器。
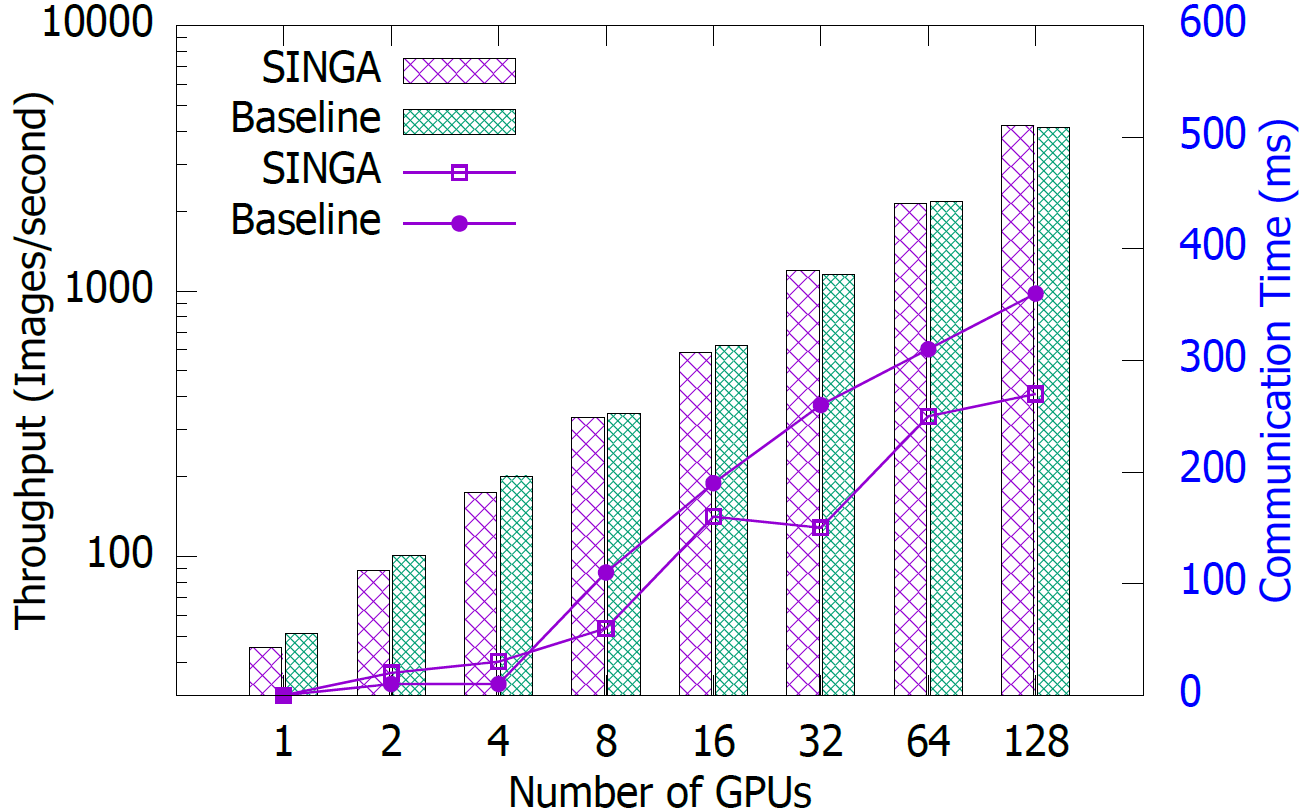
可扩展性测试。条形为吞吐
量,折线形为通信成本。